Abstract
Sentiment analysis is the task of extracting subjective or qualitative information from textual data. It can involve various scientific domains, including Machine Learning, and more particularly Natural Language Processing. Distinguishing a positive from a negative sentence can be a useful tool to improve recommender systems or, in the case of tweets, to capture the general mood of a population.
This report compares several ways of dealing with this task involving various data preprocessing, embedding and classification methods, the best pipeline achieving an accuracy of around 90%. It also provides an analysis of what worked or didn’t work as well as expected, and introduces leads to further improve these results.
Introduction
The goal of this project is to predict as accurately as possible the general tone of 10000 tweets: positive or negative. To achieve this goal, a training dataset of 2.5M labelled tweets is used. What makes the task a challenge is that tweets cannot be treated as mere sentences from a book. They contain grammar mistakes, uncommon abbreviations and twitter specific punctuations, that have strong influence on the final sentiment of the tweet. As an illustrative example, one could remember a past trend in which “>>[>]+” denoted a happy feeling, whereas “<<[<]+”” denoted the opposite.
Starting from the ground up, the first step was to build a preprocessing adapted for tweets. It was then chosen to apply down-to-earth feature extraction techniques and classifiers to have a grasp of the task difficulty, using the TF-IDF matrix. Research then lead the way towards the GloVe embedding and neural networks, yielding slightly better results. As the accuracy was struggling to overcome the 80% threshold, RNN came to the rescue and performed better than the other models. A major issue that was faced is the computing power, as free plans provide generally small GPU and RAM.
Models and Methods
The general pipeline consists in three relatively independent steps, all of which were tested with several methods:
- Preprocessing: transforming the raw tweets in order to clean them and make them more relevant for our models.
- Embedding: representing the tweets as vectors.
- Classification: classifying these vectors into two classes: positive and negative.
This paper presents three methods for tweeter sentiment analyzis: a method with basic ML techniques and custom-made features, a method with RNN and a method based on Bidirectional Encoder Representations from Transformers.
Preprocessing
As a starter, a raw analysis was carried out on the training dataset, whose goal was to determine the kind of preprocessing to apply. It mainly consists in comparing if some characteristics (letters, symbols, length) are a good indicator of the tweet sentiment and could be used as additional features in our future models or could be removed to lighten the dataset. For instance, Figure 1 shows for example that long tweets tend to be much more frequently negative. It was also noticed that negative tweets are more likely to contain urls and exclamation marks. In parallel, stopword removal techniques were tried using Spacy’s list of English stopwords as a basis. As the list is short, we manually refined it by keeping words bearing strong sentiments, such as “against”, “without”, “nowhere” for instance. Finally, small transformative function were tried: replacing emojis by words of equivalent sentiments, removing matching parenthesis, parsing hashtags, …
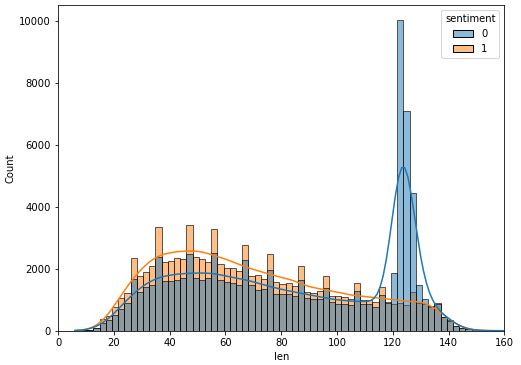 |
|---|
| Figure 1 : distribution of tweets’ length |
In addition, twitter’s semantic uses bunches of abbreviations and letters in words are sometimes repeated to emphasize its meaning. As an attempt to reduce the complexity of the dataset, a function removing duplicated letters, as well as a short dictionnary replacing word contractions such as “where’s” or “she’ll” by their complete form were applied.
Finally, the sentiment analysis tool VADER was used to spot words that were particularly positively or negatively connotated, and it was decided to duplicate them in order to increase their influence. In addition to this use, the sentiment analysis of vader was also used as extra features for the tweet embeddings.
Down-to-the-earth methods
Embedding techniques
TF-IDF matrix
The first shot was given with the classical document embedding algorithm: TF-IDF, which estimates the relevance of a word w in a given document d by using the frequency of w in d and the total number of documents in which w appears. This yields a document embedding with as many features as there are words in our vocabulary, which is a lot, but this number can then be reduced performing dimensionality reduction.
Pre-trained GloVe vectors
Noticing the poor results of the previous embeddings, research was led towards state-of-the-art embeddings algorithm, such as GloVe, based on the cooccurence of words and matrix factorization, and word2vec. After having tried to train GloVe ourselves, the lack of computational power required the use of pre-trained word embeddings from GloVe’s website. Attempts to enhance this embedding were tried, by adding features based on length and VADER. As this method struggled to overcome the 80% accuracy threshold, a more complex model was searched.
Classifier
Following the generation of the TF-IDF matrix or that of the GloVe embeddings, classical ML classifiers were tested such as standard logistic regression, SVC, random forests, and simple fully-connected neural networks (NN). Hyperparameters were optimized using gridsearch for the most promising classifiers. Even though some of the classifiers used were bound to yield poor results (e.g ridge regression) for the classification, it gave a first insight of the starting point of the project. Due to an overall poor result of this pipeline and classifiers, new types of classifiers and embeddings techniques were searched.
RNN with GloVe and custom embeddings
Embedding
Pytorch provides an Embedding layer which, combined with a fully-connected layer, can learn embeddings in a word2vec way (for instance, approximate the probability \(P(w_i | w_{i-1}, w_{i-2})\)). Knowing that tweeter’s vocabulary is broader than the usual that of the daily english language1, there were lots of tokens of the corpus with no corresponding embeddings in the GloVe file. As this layer learns the embeddings of each token given all the labelled tweets, the resulting embedding is believed to be more specific and adapted to the provided dataset.
To ease the training of the embedding layer, it was also tried to initialize it with the pretrained GloVe embeddings.
Classifier
Finally, the discovery of recurrent neural networks (RNN) and of the embedding layer of the Pytorch library took the challenge to another level. A RNN using an embedding, a LSTM and a fully-connected layer was then designed, trained, evaluated and refined (see Figure 2). This network takes as input a vectorized tweet, which is an array of integers where the integer k at the index i is the index in the word in the vocabulary at position i in the original tweet. It is thus mandatory to set a seq_length variable, which is the length of a vectorized tweet. Noticing that the distribution of number of tokens in a tweet (Rarely above 60 tokens in a tweet), it was decided to set seq_length to 40 and trunc the tweets accordingly. The authors are aware that this value can be considered as arbitrary, and propose to remember it as an hyperparameter for future investigations. Shorter tweets are padded with zeros. The following lead has not been investigated due to time constraints, but should be considered in future investigations: padding of shorter tweet could be done by repeating the tweet until seq_length tokens have been reached.
On a dedicated platform, the training lasted ~5h. For this reason, this model and its variations have been evaluated with a classical train (0.8) / test (0.2) set duo, and not with a cross-validation. This also holds for the following models.
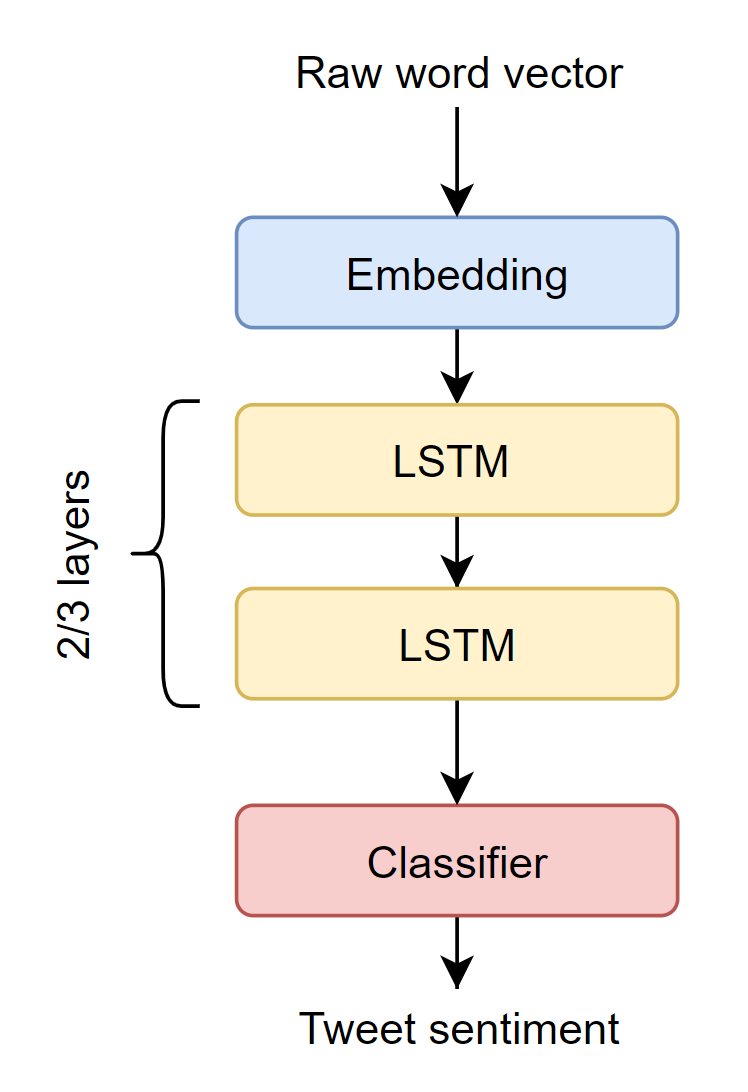 |
|---|
| Figure 2 : Illustration of the RNN network used |
BERT: Bidirectional Encoder Representations from Transformers
BERT is a recent Transformer-based machine learning technique for NLP pre-trainings developed by Google. The ground-breaking change brought by this technique was that it includes the context of words in a sentence, when TF-IDF or GloVe embeddings could only include a contribution per word but not their order. BERT is designed to pre train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. The pre-trained used for this tweeter-sentiment analyzis were available in the python library transformers.
Pretrained transformers with GRU top layer
Embedding
We used the base bert-base-uncase pretrained model from transformers in order to tokenize the tweets. They are then passed through the pretrained NN which gives an output of 768 features. This part was frozen during training.
Classifier
The classifier consisted in 3 layers of GRU 768 –> 258 (as explained in the last part), to a linear layer 258 –> 258 –> 1 with a dropout of 0.25. The training only consisted in training these upper layers, as the pre-trained BERT layers where frozen. With this constraint, the training was pretty fast (20 min per epoch on a V100 GPU) and the convergence fast.
Finetuning pretrained models with custom dataset
Embedding
The on-top GRU layers quickly gave good results, but seemed to be stuck pretty fast. The second solution was then to fine-tune the entire BERT model. In this case, the same embedding was used (with the BertTokenizer from Transformers) but the hidden BERT layers are also trained.
Classifier
The classifier was a 1-hidden-layer feed-forward network 768 –> 768 –> 768 with dropout 0.25 and tanh activation function. This layer is added on top of the output of the last BERT layer and implemented using the transformers library.
Training hyperparameters choice
Batch size
Several batch-sizes were tested on the GRU model, from 128 to 512. On the fine-tuned BERT, we kept a batch-size of 25 as the training was already taking hours (2h per epoch on a V100 GPU).
Optimizer
Several optimizers were tried: Adam, AdamW (link paper) with several learning rates. Although 1e-3 was a nice choice for training the GRU layers, 1e-5 was better suited for fine-tuning the BERT model.
Scheduler
A scheduler was used for training the BERT model in order to adapt the learning rate to the number of iterations. The GRU model did not have any scheduler.
Results
TF-IDF with standard classifiers
As explained above, there are multiple ways of embedding document into vectors. One of the most common ones, which is especially used in information retrieval, is TF-IDF. We combined TF-IDF with several classifiers, and tested it with and without the previously detailed preprocessing. Cross validation was used to optimize various hyperparameters.
It turned that the models showed better results when only using nltk’s stopwords removal functionality, and not our own preprocessing. Without our preprocessing, the prediction results are summarized in Figure 3.
 |
|---|
| Figure 3 : Accuracy of TF-IDF combined with various classifiers. NB: Naive Bayes, RF: Random Forest. Optimized: after hyperparameter optimization |
After getting these results, we tried to improve our models’ performance by performing PCA and feature engineering. It turned out that dimensionality reduction significantly deteriorated the results (by 3 to 6 percents, depending on the classifier and the chosen embedding dimension. The feature engineering, whose details are explained below, did not compensate this loss.
GloVe embeddings with standard classifiers
Training a GloVe model from scratch requires a lot of time and computing power, which is why pretrained embeddings downloaded from the web were mostly used for this part of the project. However, the results of this model were far less promising than the ones that will be detailed in the next paragraph.
To show the performance of the GloVe-based model, a graph showing the accuracy of a Random Forest using GloVe embeddings is provided in Figure 4.
 |
|---|
| Figure 4 : Performance of Random forests with GloVe embeddings |
RNN & embedding layer
A disappointing but not surprising result is that the model performed generally worse (arround ~ -2% ) with a preprocessing than without (raw tweets). This could be explained by the fact that sentiments are also conveyed by the way the words are written in tweets (duplication of letters to emphasize the meaning, specific punctuation, …). In this case, preprocessing would negatively influence the following the sentiment analysis on the corpus. Here, the embedding layer learns the vocabulary as is, and seems to adapt better to a non-preprocessed corpus. Noticing this behaviour, other configurations have been tested without processing.
Setting the initial weights of the embedding using the pretrained GloVe embeddings did not help either, dropping even more the accuracy of the model.
Finally, it was noticed that an increased number of LSTM layers and number of nodes in the linear layer would slightly increase the accuracy of the model. For lack of computing power, extensive hyperparameter optimization was not carried out and is left for better provided readers.
Results are summarized in Figure 5. The first model yielded an accuracy of 0.87 on AIcrowd.
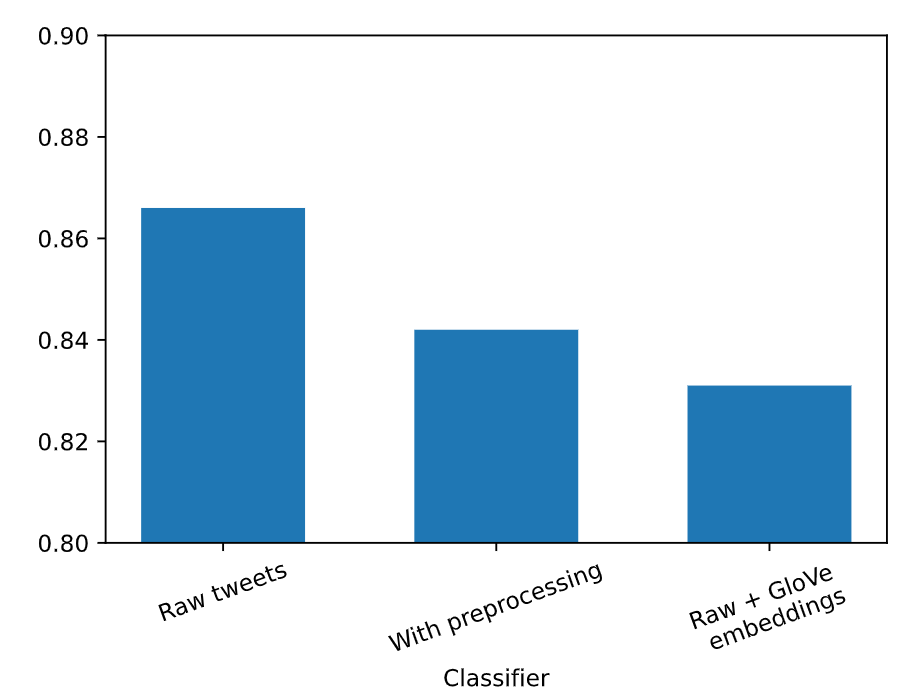 |
|---|
| Figure 5 : Performance of RNN with various configurations |
BERT models
The embeddings for the BERT models were pretty similar to the GloVE ones, with the difference that tokens such as *
Pretrained transformers with GRU top layer
The first results with this model were pretty encouraging: after only a few epochs, accuracy was close to 87.6%. Unfortunately, this value was a peak, and many more epochs did not improve the result. Several alternatives to improve the final accuracy limit were tried, such as increasing the batch-size to slow down convergence and improve the gradient descent. This did not improve the result, as the maximal accuracy reached was 87.2%. Changing the number of GRU layers did increase training time but did not improve results either. Adding more nodes to the hidden layer only made the convergence worse (not even more than 75% of accuracy after a few epochs, while drastically increasing the epoch duration). The accuracy of state-of-the-art sentiment analyzers based on BERT is a lot better than these, so the last approach was to fine-tune the BERT model. Unfortunately, unfreezing the BERT layers did not work as the computing time was more than tripled, and the convergence abnormally slow. Furthermore, the learning rate that was adopted to train the GRU layers was not appropriate to fine-tune BERT.
Fine-tuning BERT model
The next step to further improve our predictions was to fine-tune the BERT model. To do so, the BertForSequenceClassification model from transformers was used and trained on our vocabulary. After several grid-search tests on a smaller dataset of tweets, the values kept for training were \(lr = 1e-5\), cosine_scheduler with warmup of 40000 steps, with a batch-size of 25.
The model was trained on 6 epochs, but unfortunately it was overfitting after 2 epochs, with a maximal accuracy of 90.3% on a validation subset of 100000 tweets and 89.7% on AICrowd (ID 110032). The lack of computing power did not allow us to rerun with a bigger batch-size on more epochs, but we may suspect to slightly improve even further these results.
Discussion
These results are a good illustration of the evolution that was accomplished in the last years concerning sentiment analysis. Even though standard classifiers gave interesting results, they were wiped out by the NN-based methods.
First, RNNs showed that they could easily outperform standard classifiers, while still being fast enough to allow experiments and fine-tuning, even to a limited extent. Their ability to capture information carried in the order of words gave them a decisive advantage on standard pipelines.
However, it was with transformers that the best results were achieved. Though it was more complicated to run experiments and to optimize or fine-tune this model, the fact that pre-trained weights can be found online allowed significant improvement of the previous results.
All this being said, the fact that no really successful preprocessing was achieved despite various attempts can be considered disappointing. This could be explained by the fact that, as mentioned earlier, sentiments are sometimes carried by subtle notions and word variations, which would often be overlooked by the usual NLP preprocessing tools. Also, it can be assumed that the models used here, especially the neural networks, were powerful enough to handle the data without it going through preprocessing functions such as stemming or lemmatization.
Summary
A lot of different methods were compared, and several gave interesting, if not very satisfying results. The most state-of-the-art neural-network approaches turned out to be the most successful ones, and lead to an accuracy of around 90%, which we can imagine is pretty close to human performance for the sentiment analysis task for tweets that sometimes only have a few words.
Indeed, as George Sand once said, “sentiments must be judged based on actions, rather than words”.
-
A word can have k ways to be misspelled, all of them are likely to be used in the dataset ↩